语言服务器简史
develop lsp
让我们来稍稍看一下代码编辑器“引擎盖下的秘密”。
编辑器和集成开发环境(IDE)
享受有趣的命令,带着屏幕上闪烁的一切。
– Bill Joy (vi 之父)
与编辑器圣战(黑客文化和自由软件社区争论哪一种代码编辑器更好)相对的, 编辑器和集成开发环境的选择也常常是争论的焦点。用户要么:
- 为每一种语言安装一个集成了编辑器、编译器(或者解释器, REPL )、调试器、构建系统的集成开发环境
- 开箱即用
- 同时忍受多个集成开发环境带来的快捷键、交互界面不一致带来的用户体验问题
- 为所有语言选择同一个编辑器
- 让用户编写任何语言时都可以享受相同、熟悉的用户界面并不需要记忆新的快捷键
- 同时面对如何配置该编辑器以让每一种语言的开发工具都能支持该编辑器的配置难题
目前大多数用户普遍的共识是:
- 对于萌新,集成开发环境可以省去配置的麻烦,前提是买个容量大点的硬盘(笔者在学会使用编辑器之前电脑最多同时装过十多个不同的集成开发环境,有些非常占用空间)
- 对于有配置编辑器经验的开发者,答案不言而喻,毕竟谁也不想记忆十多个不同的集成开发环境的快捷键
那么问题来了:
每一种语言的开发工具(不光是编辑器、解释器、调试器、构建系统,还包括语法高亮、类型标注、注释自动生成等工具)是怎么支持编辑器的? 为何用户用编辑器打开一个文件就能看到语法高亮?为何用户执行一个快捷键就能跳转到函数的定义?为何用户写了有错或虽然没有错但不太好的代码会有错误或警告的悬停? 为何用户能得到代码补全?在这一切的背后到底隐藏了什么秘密?
语言服务器协议(LSP)问世前的编辑器
一般的,编辑器允许用户通过编写插件的形式获得对开发工具的支持,例如:
- (neo)vim: 允许用户编写 vim script/python/ruby/perl/lua/js 等多种语言编写插件。这是因为有些 vim script 实现不了的功能必须依赖其他语言,比如某个插件必须用到 python 模块,那就干脆
import vim直接在 python 里写 vim 插件算了 - emacs: emacs lisp 是专门用于开发插件的 Lisp 方言
- eclipse: eclipse 插件都是 java 的包
- sublime text: python
- Atom/VSCode: js
有 $n$ 种编辑器和 $m$ 种语言的开发工具,那么我们要开发 $n \times m$ 个插件。
支持多种语言的工具,完成功能后退出
出于方便,开始有对 m 种语言提供某一功能的统一工具出现。
- ctags: 提供了对 41 种语言的变量、函数定义跳转功能的支持。不需要 $41 n$ 个插件,只需要 $n$ 个!
- gtags: 类似
- cscope: 不光定义跳转,也支持调用跳转。将纯文本格式的 tags 缓存替换成了二进制缓存。
- global: 类似
它们的原理是:
扫描当前目录下所有支持语言的文件,生成缓存文件(例如 tags)记录变量、函数定义的位置信息,查找这些信息即可。当然生成缓存文件其实很慢,这考验编辑器插件的开发者能不能正确编写出异步的插件。如果只是简单的同步插件,用户光启动编辑器就要等半天……
!_TAG_FILE_FORMAT 2 /extended format; --format=1 will not append ;" to lines/
!_TAG_FILE_SORTED 1 /0=unsorted, 1=sorted, 2=foldcase/
!_TAG_PROGRAM_AUTHOR Darren Hiebert /dhiebert@users.sourceforge.net/
!_TAG_PROGRAM_NAME Exuberant Ctags //
!_TAG_PROGRAM_URL http://ctags.sourceforge.net /official site/
!_TAG_PROGRAM_VERSION Development //
main main.c /^int main(int argc, char *argv[])$/;" f
类似也有支持多种不同语言的代码格式化工具 astyle, prettier 等等,动机同上。
支持多种语言的工具,以守护进程的形式在后台运行等待与编辑器的再次交互
这其实已经是语言服务器的雏形了。 YouCompleteMe 提供了对多种语言的代码补全支持。 YouCompleteMe 没有流行开来,不过不必惋惜因为我们马上就要介绍语言服务器了。
语言服务器协议
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。
– David Wheeler (剑桥大学计算机科学教授)
语言服务器协议成功将 $n$ 种编辑器和 $m$ 种语言的开发工具的 $n \times m$ 个插件开发难题简化为开发 $n$ 个语言客户端和 $m$ 个语言服务器的 $n + m$ 个软件通过 LSP 通信的问题。
一图胜千言:

语言服务器协议通常提供以下功能:(完整功能见官网)
文档悬停
- 显示关键词的文档。
- 函数、变量的定义、注释
- 光标下单词的翻译


代码补全
根据上下文和用户输入的前几个字符(例如 pr )预测用户的完整输入(例如 printf()),并按优先级排好,预测结果包含预测的类型(例如关键词、函数、变量会有一个不同的标记,例如 k, f, v)。可以显示对应的文档悬停。
补全源:补全的来源,包括:
- 关键词、函数、变量等某种语言独有的补全源
- 词典、 emoji 表情、文件名等等
- 输入法。对!用户输入
nihao补全你好! - 代码片段。例如:
- 输入 inc 补全为
#include <|>,|是光标 - 输入
p, 补全为<p>|</p>
- 输入 inc 补全为
- 预测。通常是机器学习模型预测的结果:


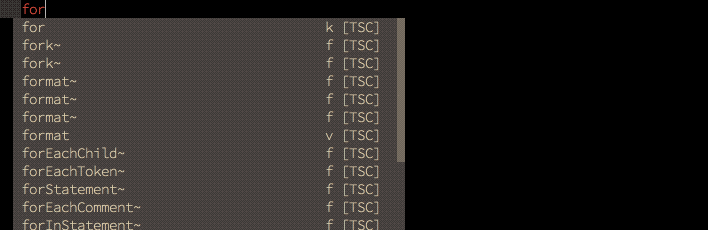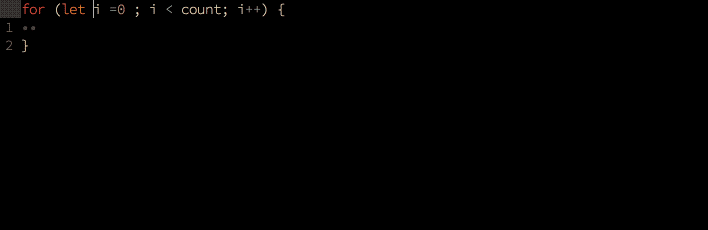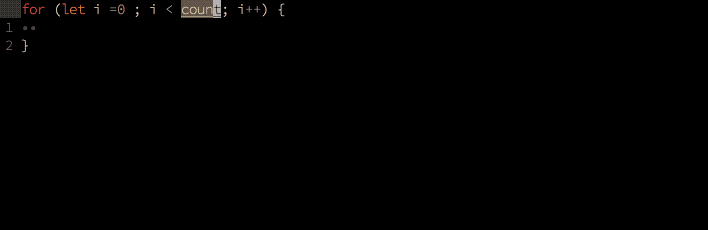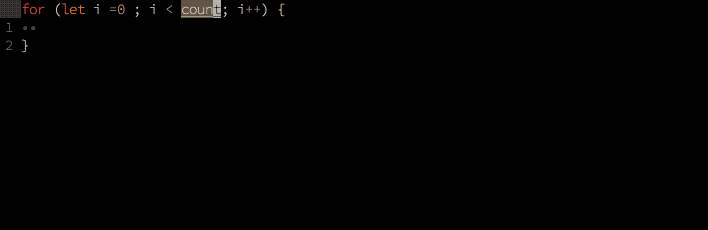
代码格式化
- 部分格式化:格式化文档中的某一个给定范围,其余部分不变。
- 全文格式化
代码诊断
通常是某些事件后自动触发(例如文件打开(didOpen),文件修改(didChange))。显示提示、信息、警告、错误 4 个等级的诊断。 通常可以有:
- 类型检查:函数定义是
def echo_input(input: str) -> str:, 结果却return None - 格式:
echo_input( input)应该是echo_input(input) - 未定义的变量,未使用的变量
- 拼写:怀疑是错误的拼写,或者已经被确认一定是错误的拼写,例如 codespell 就是一个专门收集拼写错误的开源项目
- 不合适的语法,像 alexjs 连可以引起性别歧视的单词都会给你警告……
- 编译的警告和报错:下图正确的包名应该是 autopep8

定义、声明、引用跳转
可以用正则表达式查找,但一般的做法还是解析抽象语法树。
注意:有些语言存在头文件,定义、声明可以不在一个位置。
命令
执行某个命令。可以是同步、异步,也可以开子线程。通常是某些语言专属的功能。例如:
- 跳转到某个 C 文件对应的头文件
- 运行某个代码块并返回结果,常见于 markdown
- 验证 toml/json/yaml 是否正确
基本上不同语言很难普遍存在的功能都会放在这里。
代码操作 (code action)
笔者目前不是很清楚,但似乎是某种给定范围的命令,类似 vim 带有范围的命令。
- 将某个范围里的某个被怀疑有错的单词修正或加入到字典,例如下图。
- 从某个范围的代码的类型标注自动生成 docstring 模板
语言客户端
语言客户端即支持语言服务器协议的编辑器。分为 2 种:
本身不支持语言服务器协议,但可以通过语言服务器协议插件成为语言客户端
以 vim 为例:
coc.nvim
这应该是 Vim 最有名的 LSP 插件。严格来说它不仅是语言服务器,还提供了一套用 js 编写 vim 插件的框架,或将 VSCode 插件移植到 Vim 的一套相仿的 API 。
可以通过修改 coc-settings.json 使能某个语言服务器,或者为某个语言服务器创建 Coc 插件来使能该语言服务器。
vim-lsp
vim script 在很久之前不支持异步,所以在此前有相当多的 vim 的 LSP 插件都只能用别的语言编写,这不可避免的引入了依赖项。 所以这个用纯 vim script 实现的异步 LSP 插件值得一提。
原生语言客户端
注意,即便原生支持 LSP ,也可以有插件简化使能语言服务器的配置。
配置方法参见文档。
语言服务器
语言服务器通常可以分为通用语言服务器和专用语言服务器:
- 通用语言服务器:支持多种语言。
- 通过配置。例如:
- diagnostic-languageserver: 通过修改一个 json 来支持多个语言的诊断和格式化。在语言服务器问世之前有很多语法检查工具和代码格式化工具,可以通过配置通过命令行调用它们从而为一个通用语言服务器提供对某种语言的支持。
- efm-langserver: 最早的通用语言服务器
- 通过编程来实现一种专用语言服务器,或者叫语言服务器源代码开发工具 SDK 。例如:
- vscode-languageserver-node: 名字上带有 VSCode ,但实际上支持所有语言客户端
- pygls: 通过继承一个通用的类再实现具体的功能(补全、文档悬停等)
- 通过配置。例如:
- 专用语言服务器:支持某一种语言。官网有个列表。
笔者自己在学习中也基于 LSP SDK 动手实现了一些语言服务器:
- mutt-language-server: (neo)muttrc
-
termux-language-server:
- Android termux
build.sh - ArchLinux/Windows Msys2
PKGBUILD - Gentoo portage
ebuild
- Android termux
-
requirements-language-server: python pip
requirements.txt - autotools-language-server: GNU autotools 。 嗯,不过笔者已经决定以后都用 CMake 了。 CMake 用户可以用 cmake-language-server。
- bitbake-language-server: openembedded bitbake 。某个嵌入式 Linux 发行版使用的构建系统。笔者正被老师要求把模型部署到这个嵌入式平台的某个项目整得焦头烂额……
- expect-language-server: expect’s tcl script
- xilinx-language-server: xilinx vivado/vitis’s tcl script
- zathura-language-server: zathurarc
- sublime-syntax-language-server: sublime text/bat sublime-syntax
语言服务器协议之外
并不是所有编辑器需要的功能都被语言服务器协议囊括在内了。
语法高亮
Vim Syn
Vim 原生是通过 vim script 的 syntax 和 highlight 2 个关键词来实现语法高亮的。比如:
syn keyword requirementsKeyword implementation_name implementation_version os_name platform_machine platform_release platform_system platform_version python_full_version platform_python_implementation python_version sys_platform contained
syn match requirementsPackageName "\v^([a-zA-Z0-9][a-zA-Z0-9\-_\.]*[a-zA-Z0-9])"
syn match requirementsVersion "\v\d+[a-zA-Z0-9\.\-\*]*"
" ...
hi def link requirementsKeyword Keyword
hi def link requirementsPackageName Identifier
hi def link requirementsVersion Number
" ...
再由 colorscheme 插件定义 Keyword, Identifier 到底应该是什么样式。用户也可以通过重新 highlight default link 将特定于某一种语言的高亮组高亮到其他高亮组。
Vim 社区也有讨论到底要不要支持 Vim Syn 以外的语法高亮方式。
tmLanguage
TextMate 使用的一种描述语法高亮的 XML ,后被 VSCode 等广泛采用。但编写 XML 实在是太不友好了!
sublime-syntax
Sublime 使用的一种描述语法高亮的 YAML ,语法与 tmLanguage 兼容。后被 bat 采用。
name: Requirements.txt
scope: source.requirements-txt
contexts:
main:
- match: (?i)\d+[\da-z\-_\.\*]*
scope: constant.other.version-control.requirements-txt
- match: (?i)^[a-z\d_\-\.]*[a-z\d]
scope: variable.parameter.package-name.requirements-txt
# ...
Treesitter
是目前唯一支持增量式语法高亮的引擎:用户修改文本后只需要发送改动的部分将可以计算出如何从修改前的语法高亮得到修改后的语法高亮,不需要将完整的文本重新计算语法高亮。卖点就是性能。不过实现难度很大,像之前的语法高亮引擎要支持某种新语言只会正则表达式的开发者需要编写一个 vim 脚本或 XML/YAML 即可,而 treesitter 需要创建 1 个二进制程序来解析文本生成一个抽象语法树——这也带来了分发上的难题。而且实现难度很大也导致来很多语言的 treesittier 实现有很多 bug 。
- Neovim 已经原生支持 treesittier 。笔者目前观测到的错误的语法高亮似乎都可以通过禁用 treesittier 来消除所以编写 treesittier 插件看起来真的很难呀!
- VSCode 有使用 treesittier 的插件。
- Vim 社区目前还在讨论到底要不要支持。
查找列表
尽管 Coc.nvim 和 VSCode 都有内置的查找列表功能,但它确实不属于 LSP:
- quickfix: Vim 原生的列表窗口,通常配合
compiler/*.vim使用,编译完后显示报错的信息在名为 quickfix 的特定窗口。不支持模糊匹配。 - leaderf: python 实现,悬浮窗口相当惊艳。
- coc-list: 悬浮窗口支持还是太难了
- fzf: 专门用于模糊查找的软件,封装成编辑器插件即可。 Go 实现
- skim: fzf 的 rust 实现。命令行 API 基本兼容。
其他
$ tree an_example_vim_plugin
.
├── addon-info.json
├── autoload
│ └── requirements
│ ├── utils.vim
│ └── ...
├── compiler
│ └── pip_compile.vim
├── doc
│ └── requirements-vim.txt
├── ftdetect
│ └── requirements.vim
├── ftplugin
│ └── requirements.vim
├── LICENSE
├── README.md
└── syntax
└── requirements.vim
indent/*.vim 的缩进可以看成代码格式化的特例。 compiler/*.vim 可以看成代码诊断的特例。除去之后剩下:
- 文件类型识别:根据后缀名和文件内容识别文件类型。例如 vim 插件中的
ftdetect/*.vim。 - 注释符:定义在 vim 插件中的
ftplugin/*.vim。 - 代码折叠:定义在 vim 插件中的
ftplugin/*.vim。现在 treesitter 有实验性支持。 - 文件对象:定义在 vim 插件中的
ftplugin/*.vim。现在 treesitter 有实验性支持。例如:(以 Vim 快捷键为例)- 当用户按快捷键
daf删除 (delete) 一个函数时,范围是多大?不同语言的函数定义是不一样的。 - 当用户按快捷键
y2al复制 (yank) 2 行 时,范围是多大?不用语言的续行符不一样。
- 当用户按快捷键
- 其他定义在
ftplugin/*.vim的功能。
 |
 |
 |